Transformers
Fancy state-of-the-art language model, at least for a while (?).
Some random notes on the transformer architecture.
H2 Motivation
H3 From RNN to attention-based models
Approach 1: RNN based model - encode the input with an RNN, and use an RNN to decode the output from the encoding.
Approach 2: Attention when decoding - look back at what the encoder is doing while decoding.
Problems with recurrent models:
- encoding bottlenecks - the amount of information between the encoder and decoder (perhaps solved by approach 2)
- linear locality - nearly by words are related more strongly, which is usually useful but not always
- Ex.
the _person_ who ............ _was_, in which related words are far away
- Ex.
- hard to parallelise - one step at a time because of recurrence
Approach 3: word window - stacking windows on top of each token that examines tokens in a window, much like a CNN.
Problems
- What about long distance dependency? Stacking windows or increasing window size can help, but not guaranteed.
Approach 4: attention within the sequence - with the principle that all word should attend to all words, we apply attention to entire sequence at each position in each layer.
This looks promising for what we’re trying to solve!
- O(1) interaction between any two words
- Parallelisable in time (but not in depth of layers)
(ref https://www.youtube.com/watch?v=ptuGllU5SQQ)
H2 Self-Attention Building Blocks
- Attention operation
- queries $q_{1..T}$ in $\mathbb{R}^d$
- keys $k_{1..T}$ in $\mathbb{R}^d$
- values $v_{1..T}$ in $\mathbb{R}^d$
- Self attention: $q_{i}$, $k_{i}$, $v_{i}$ are from the same source sequence, call them $x_{i}$
- Attention affinity
- $e_{ij}$, affinity between $q_{i}$ and $k_{j}$, is dot product between the key and query
- $\alpha_{ij}$, attention weights from affinities, by normalizing using softmax, computed $\frac{\exp \left(e_{i j}\right)}{\sum_{j^{\prime}} \exp \left(e_{i j^{\prime}}\right)} \quad$
- output $o_i=\sum_j \alpha_{i j} v_j$
- Problems and solutions:
- Self attention doesn’t know order
- So swapping tokens yield same behaviour
- Solution - add position encoding $p_{i..T}$ to $x_{i..T}$, assuming good position encoding
- One position representation
- sinusoidal
- or just learn them, note this means there’s a max length
- No nonlinerality - looks like we’re just doing lots of linear operations
- Solution - add some feed forward to process output at each layer
- Looking at future - RNN naturally don’t look at future tokens in inference, but not true for self-attention
- Solution - masking future words by settin their attention weight to -infinity
- Self attention doesn’t know order
(ref https://www.youtube.com/watch?v=ptuGllU5SQQ)
H2 Transformer Architecture
Other things added in Transformer, other than the above
- Key-query-value attention
- Idea - don’t set $k = q = v = x$, instead, they should be come from $x$ after some linear transformation. So
- $k_{i} = Kx_{i}$
- $q_{i} = Qx_{i}$
- $v_{i} = Vx_{i}$
- Intution - the transformations can bring out different aspects of $x$ depending on how it’s used in the attention operation
- These can be parallelised for entire embedding matrix
- Idea - don’t set $k = q = v = x$, instead, they should be come from $x$ after some linear transformation. So
- Multi-headed attention
- Intuition - we may want to attend to multiple places. This can be done by normal self-attention if attention weight is high at multiple places, but it’s not inherent to the architecture.
- Idea - have multiple attention heads with different $Q$, $V$, $K$ that somehow learn to pay different kinds of attention
- Each compute attention independently
- In practice, we can have each $Q$, $V$, $K$ be portion of the original $Q$, $V$, $K$ matrix. The output just needs to be divided accordingly, so same amount of computation.
- Training tricks - still very important
- Residual
- See [@heDeepResidualLearning2016]
- We put residual connection from before layer to after layer
- Layer normalisation
- Normalise to it unit mean and std within each layer
- Helps reduce variation that may make training harder
- Dot product scaling
- For high dimension ($d$) vector, dot product become large
- This could lead to uninformative gradient
- Solution: divide attention score by $\sqrt{ \frac{d}{h} }$
- Residual
- Multi-head cross-attention in decoder
- This is to let the decoder look at information from the last transformer encoder
- Notation: $h_{1..T}$ be output from encoder, and $z_{1..T}$ be input from transformer decoder
- What to do: get key and value from encoder, get queries from decoder.
- $k_{i} = Kh_{i}$
- $v_{i} = Vh_{i}$
- $q_{i} = Qz_{i}$
H3 Complicated diagrams
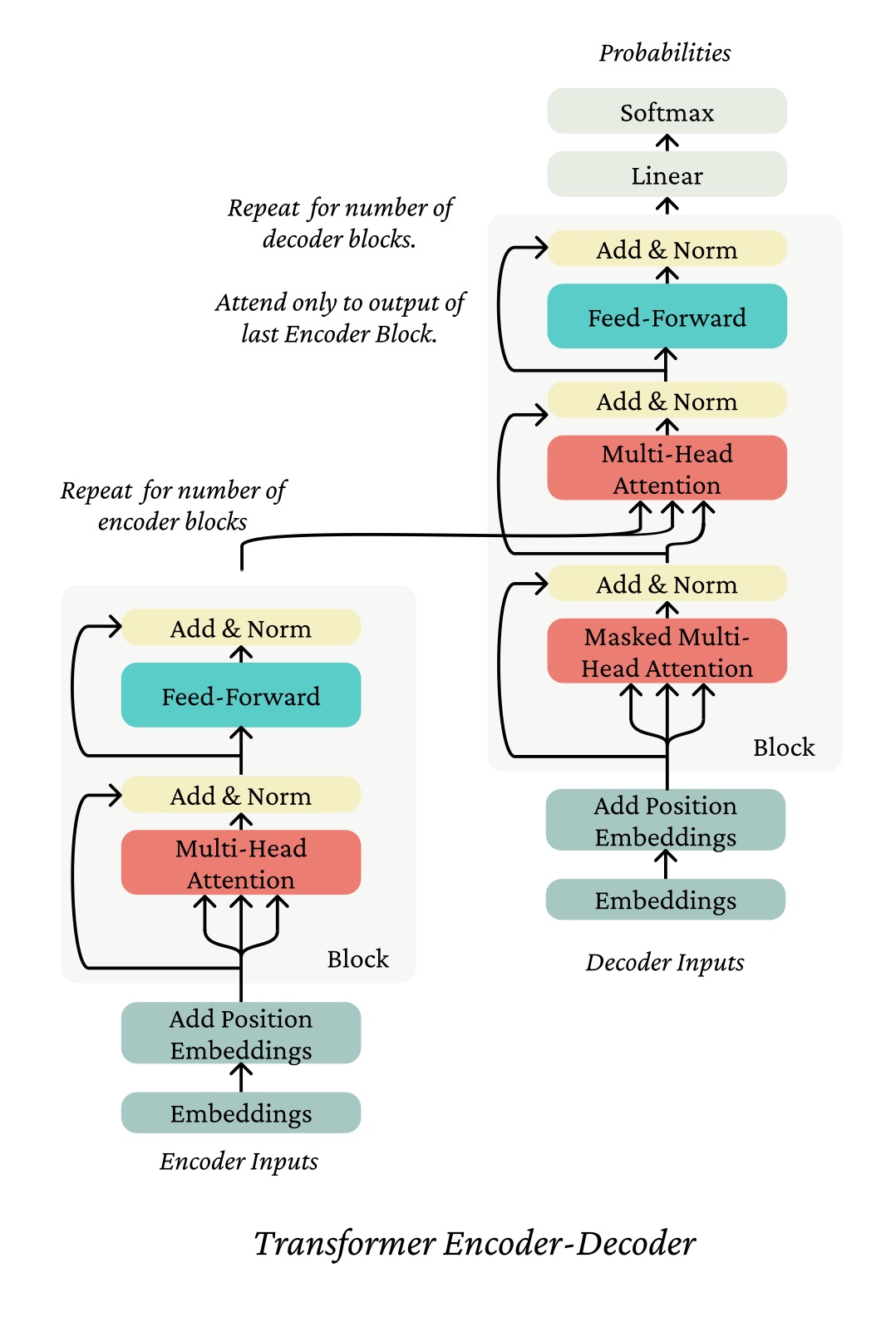
(from
https://web.stanford.edu/class/cs224n/readings/cs224n-self-attention-transformers-2023_draft.pdf)
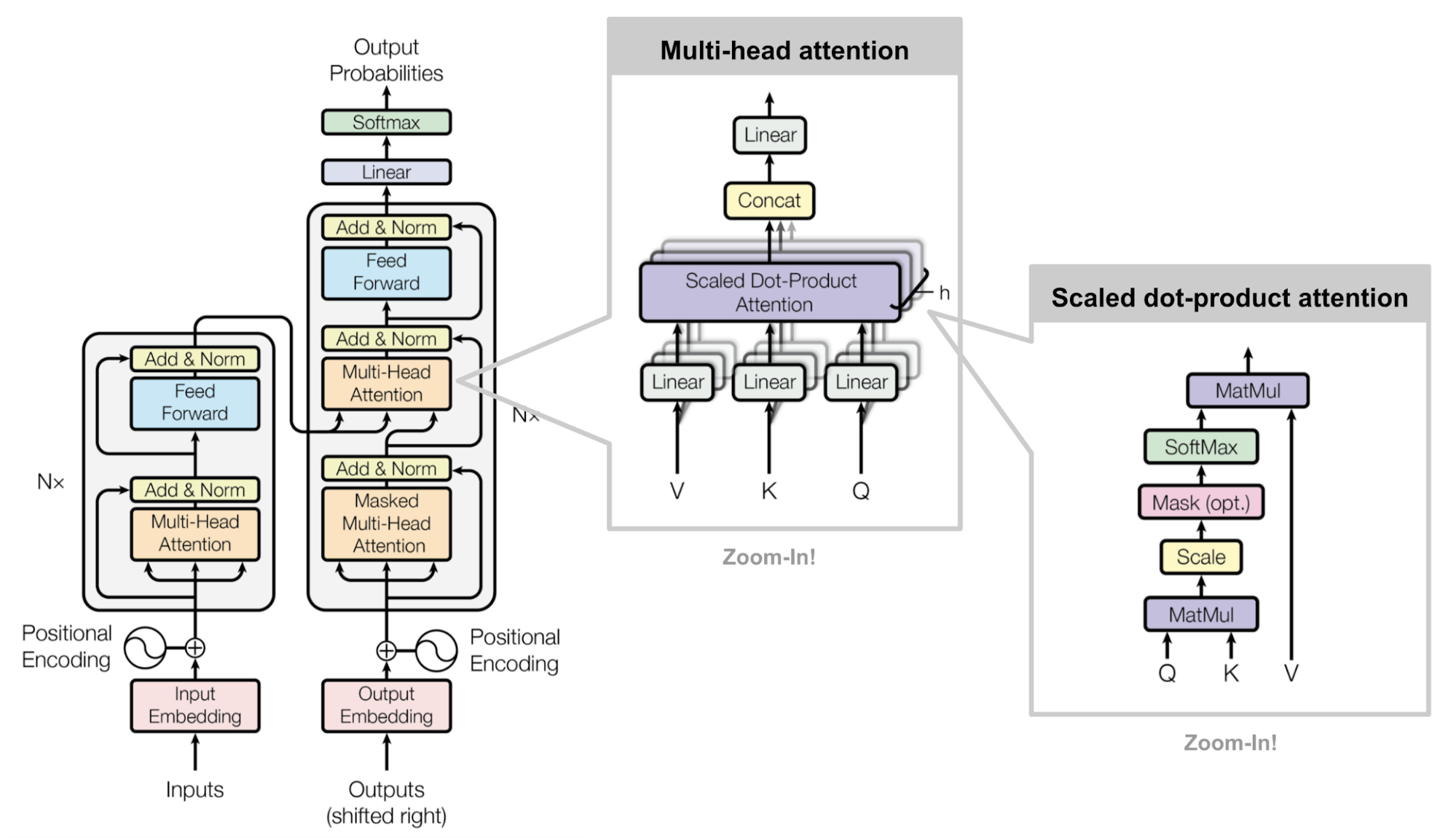 (from
https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html)
(from
https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html)
H2 Implementation
Hmm why all the diagrams if we can import (errm nope nvm)
H2 References
- @vaswaniAttentionAllYou2017
- Stanford CS224N Lecture on Self-Attention and Transformers
- https://lilianweng.github.io/posts/2018-06-24-attention/