Concurrent Programming
#lecture note based on 15-213 Introduction to Computer Systems
H2 Classical problems in concurrent programmes
- Race - what happens when scheduler do arbitrary things
- e.g. multiple threads incrementing same thing
- Deadlock - resource allocation may prevent progress (in any thread)
- e.g. printf in handler: process acquires lock, and handler may interrupt and try to acquire lock again
- Livelock / Starvation / Fairness - external events prevent progress, such as scheduler keeping you in line
- Livelock looks like making progress but never escaping from some loop, like threads requesting same resource back and forth but none ever get to use it because of interference
- Starvation is when something keeps using some resource, so others are stuck
- e.g. side street stuck when heavy traffic on main street
H2 Concurrent Server Approaches
- Process based - the common solution in the past - ex. create a child to connect to client
- Make child process, kernel takes care of interleaving
- Private address space
- See Processes
- Event based
- Programmer manually interleave
- Same address space
- I/O multiplexing
- Thread based
H3 Example problem: server
If non-concurrent server already connected to a client, second clicent gets stuck on read after connecting and sending some write. Worse still the first client can wait without closing connecting, which makes the server stuck…
- Process based
- Pros
- Easy code :) - see 30
- Need to clean up resources :)
- Cons
- Can’t share data between processes :(
- Forking is expensive :(
- can only exit with an int (only some part of the int)
- Pros
- Event based
- Idea: server keeps set of active connections (connfd array)
- Repeat:
- Check which descriptors have pending input (ask kernel)
- If listening, accept connection
- Respond to all the pending inputs
- Pros
- One address space
- Easier to debug
- Cheaper because no forking
- Cons
- More complex to implement
- Can’t use multicore
- Less concurrency control on e.g. partial HTTP request headers
- Need to hold on to partial data and switch to another request…?
- Thread based
- Pros
- less expensive to create than process and reap
- Easy data sharing
- Cons
- Very easy to go wrong
- Pros
H2 Threads
- Recall
- Process
- context + code + data + stack
- parent-child hierarchy
- Signals
- interrupting execution
- shares state
- returns to normal execution
- so not a peer thread executing!
- Process
- Thread
- Independent to each thread:
- thread context - private to thread - own copy of:
- registers
- condition codes
- stack pointer
- programme counter
- supposedly stack, so local variables too - but this is NOT private
- kernel keep they separated by some distance so they are less likely to overflow into each other
- thread id (TID)
- thread context - private to thread - own copy of:
- Shared among threads
- kernel context
- VM structure
- file descriptor table
- brk pointer
- shared lib
- heap
- read/write data
- data
- kernel context
- No hierarchy, they are associated with process (we usually designate the main one as main thread)
- Different threads can run in parallel on different cores
- Independent to each thread:
H3 Posix thread interface
pthread_create- likeforkpthread_join- likewaitpidpthread_self- get TIDpthread_exit- done with thread (note callingexitexits the process)pthread_mutex_lockpthread_mutex_unlockpthread_detach(pthread_self())- make the thread not joinable- by default, threads need to be joined
- detach to tell kernel this thread will not get joined
H3 Challenges with threads
- Unintended sharing - Multiple peer thread pointing to same thing in main thread’s stack, like
&connfdon peer thread stack pointing onconnfdon main stack - race condition
- e.g. threads getting changing value that may have changed by the time they run
- possible solution: maybe allocating arguments to each thread
- e.g. … (many others)
- e.g. threads getting changing value that may have changed by the time they run
H3 Passing argument to thread
- Malloc and free
- producer mallocs, put in argument, and make thread
- consumer gets data and free
- Casting int
- producer fit all the info in a void pointer and calls create thread on that
- consumer casts it back and interpret
- Point to stack slot - bad
- producer puts data in its stack
- consumer looks at producer’s thread
H3 Shared Variable
A variable is shared iff multiple threads have reference to it.
Since thread stacks are not private… we can have many problems
Variable mapping:
- Global
- VM has exactly one instance
- Local automatic variable (those without
static)- Each thread has one instance of each
- Local static variable
- VM has exactly one instance, like global
- So one copy per all thread!
- Exceptions
errnocan be unique per thread
H3 Synchronising Threads
Potential problem: thread reads from memory, change value, and write bad… but maybe two threads read, each change value, and each write back… and things break
Fixing races: enforcing synchronisation
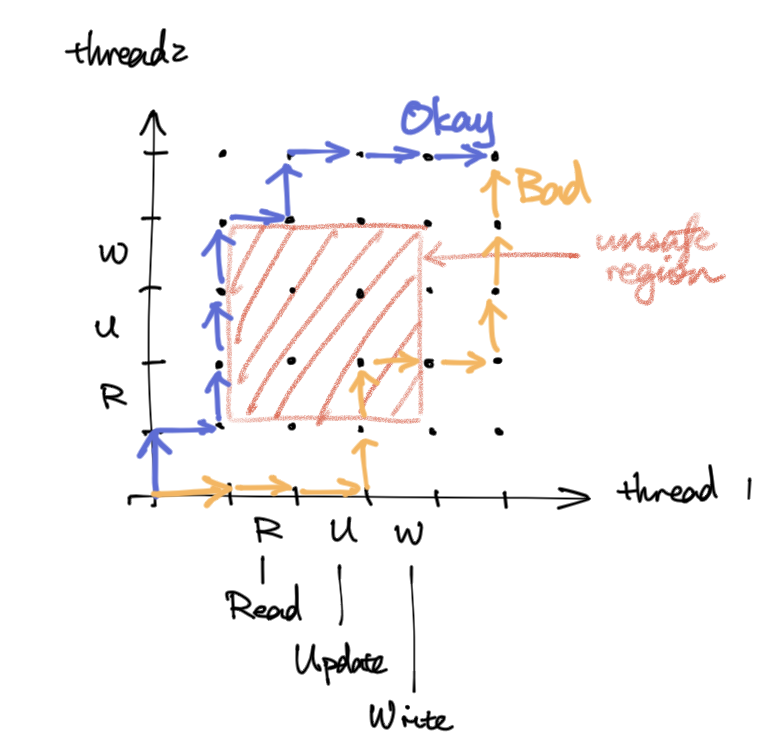
H4 Mutex - Mutual exclusion
- Usually called a lock
- Prevents the unsafe regions on interleaving graphs
- operations
lock(m)- lock it if not locked
- else, wait for some other thread to unlock and lock
unlock(m)- unlock
- Slow
- Doesn’t solve everything!
pthread_mutexnot allowed to lock and unlock across different threads by design- ex. parent incrementing counter and forking while passing that parent (this could be solved via semaphore)
- not all races involve threads
- TOCTOU bug (time of check to time of use): e.g. check permission then open file, but someone (another user, another process…) may have made change to file between that
- Solution: don’t check before use or synchronise the (check use) block
- Signal handling races
- TOCTOU bug (time of check to time of use): e.g. check permission then open file, but someone (another user, another process…) may have made change to file between that
- Edge cases
- Double lock on same thread -> deadlock
- Double unlock -> undefined
H4 Semaphore - generalise mutex
- unsigned int, but not for math
- operations on some resource
- “Prolaag” reduce
- decrement s is 0, wait for operations to happen
- Subtract 1 from and return
sem_wait(&lock);
- “Verhogen” increase
- Add 1 to
- If any thread waiting inside , resume one of them
sem_post(&lock);
- “Prolaag” reduce
- Like resource count
- Mutex is just resource count 0 or 1
- But does not have interface for getting current resource count
- No ordering requirement for and calls
- Even slower than mutex
- Use example
- Give each thread a semaphore, main thread can check if they made progress by consuming the semaphore, or the other way around
H5 Queues, Producers, Consumers
A synchronisation pattern to implement with semaphore
- Sync pattern
- Producer(s) puts thing in the queue and notify consumer
- Consumer waits for thing, remove from queue, and notify producer
- Use cases
- Multi threaded media processing
- Implementations
- 1 entry queue
fullsemaphore andemptysemaphores, keeping track of empty/full slots
- n entry queue
slotsto count available slots in queueitemsto count available items in queuemutexto make sure one one thing access the queue
- 1 entry queue
H4 Read Write Lock
- Problem: most threads read, occasionally something writes
- Implementation
pthread_rwlock_ttypepthread_rwlock_rdlock(pthread_rwlock_t *rwlock)to get read lockpthread_rwlock_wrlock(pthread_rwlock_t *rwlock)to get write lockpthread_rwlock_unlock(pthread_rwlock_t *rwlock)to release either lock
- Use cases
- Many threads read from same thread
- Reservation system read most of the time
- Problems
- Fairness
- many readers keep reading, writer starve
- many writers keep writing, readers starve
- Need algorithms to ensure fairness (i.e. no starvation)
- Fairness
H4 Atomic memory operations - hardware level
Telling compiler that something should be done in single instruction and with lock
static _Atomic unsigned long cnt = 0;
into assemblylock addq $1, cnt(%rip)
H3 Thread safe APIs
thread safe - function always producing correct results when called from multiple concurrent threads
Making things thread safe:
- Wrappin things inside internal lock
- Slows things down
- Things like
randhas internal seed…- -> Make caller responsible for allocating state
- Things like
itoahas internal buffer for result string- -> Make caller provide the buffer
- If function calls some thread unsafe function… duh it’s also thread unsafe
reentrant functions are thread safe function if it doesn’t share stuff with calls by other threads
rand_r- yes, because they all have independent variablesmalloc- no, it’s just using a lock
reentrant functions thread safe functions
H2 Thread Parallelism
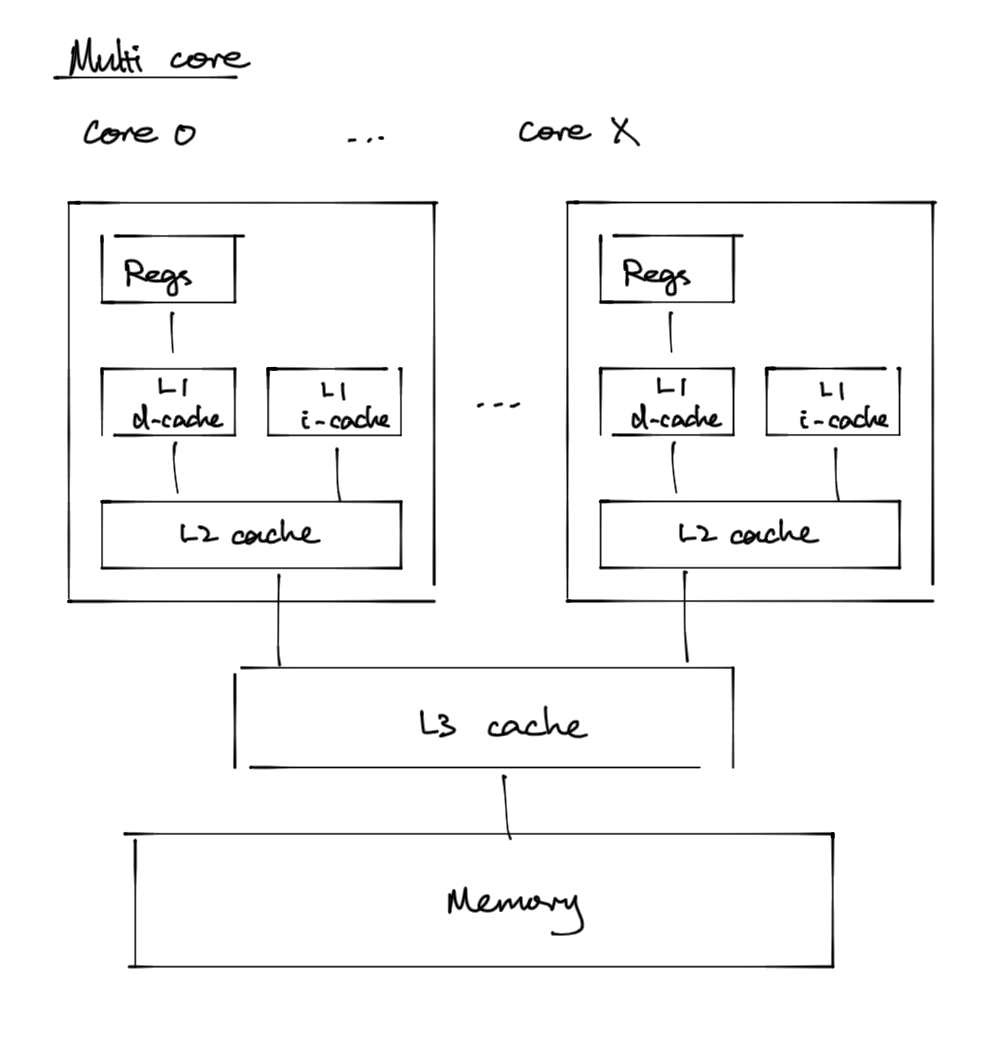
There are actually multiple cores in the processor… and things can get complicated
First is that different core may have different cache
And hyperthreading in each core…
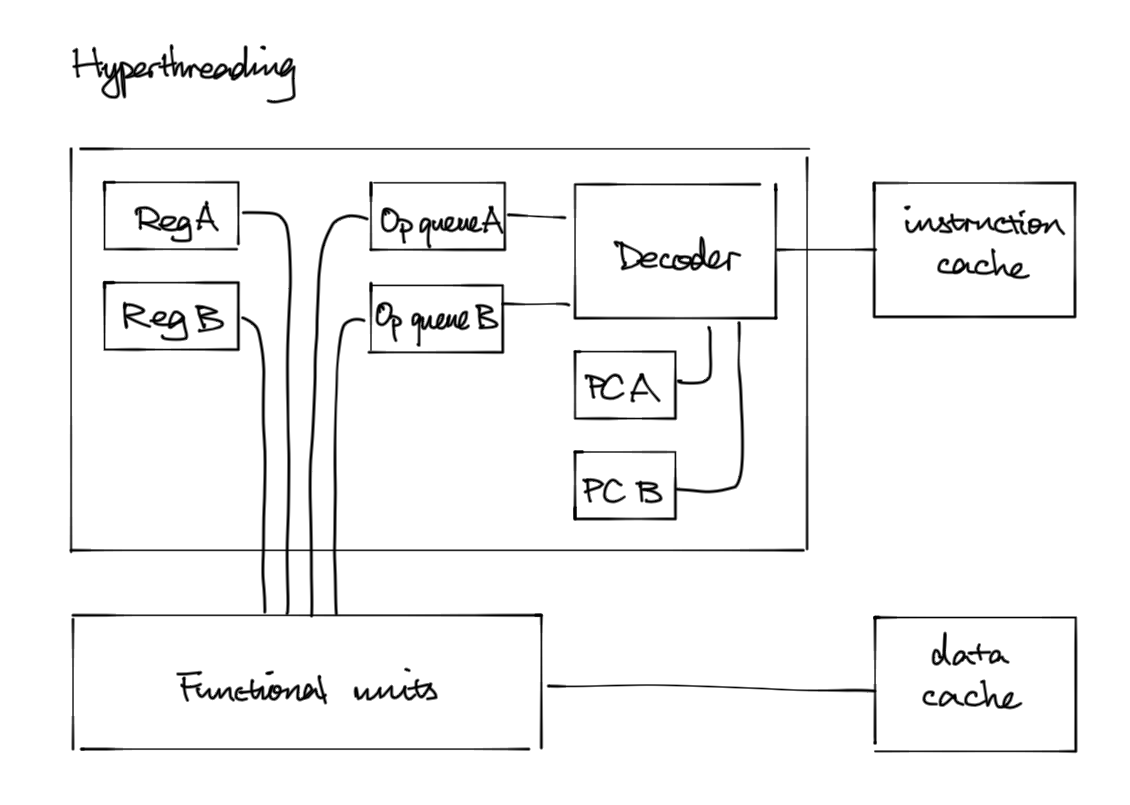
- Instruction streams
- cpu takes instructions and put them into operation streams
- operation steams goes into functional unit (viz. core) and executed in parallel
- Hyperthreading
- each functional unit can have multiple independent operation queues and registers
- scheduler figures out how to interleave threads on the same core safely
- Not just about gigahertz
- Out of order processor structure
- how well cpu predict branches
- Cache performance
- Out of order processor structure
H3 Coherence and consistency
- memory consistency - does memory behave well when running on multiple cores
- Without coordination between caches: data in one core 1 doesn’t read core 2’s cache if some var is updated by thread running on core 2.
- Some tagging mechanism helps to get bytes from one cache to another.
- Invalid - don’t use value
- shared - readable copy
- modified - writable copy
- sequential consistency - is execution order as written on each thread
- Hardware can swap operation order as long as they think they are sequentially consistent on single thread!
A good memory model:
- sequentially consistent
- viz. each thread in order, and threads interleave any way
- cache & memory behave correctly
- good intra-thread ordering constraints
- good synchronisation
H3 Thread programming disclaimers
Responsible for writing race-free code
// thread 1
X = 1
if (Y == 0) print Hello
// thread 2
Y = 1
if (X == 0) print World
This can print Hello World!!
Quantum physics of computer science
—Prof Railing
What happened? Threads may have different cache? Nope the Hello World thing happens even without cache.
Hardware optimisation might have switched order of read and write operations—they look the same on single thread, but can lead to superposition weird behaviour on multithread. Buffering read before write is 20-40 times faster so x86 does this often. (ARM is even worse as it reorders almost every memory operation. Hardware only ensures order makes sense on a single thread). Therefore memory is NOT sequentially consistent
Solution: use synchronisation
H4 Summing many numbers
Try having them share same global counter?
- Make lots of threads and have all threads increment
- 3 times faster on 16 threads, but plateaus as thread count increases
- Why? The threads aren’t sharing cache… 4th type of cache miss - so we need to go to another thread’s cache to get counter value
- Wrong answer
- 3 times faster on 16 threads, but plateaus as thread count increases
- Mutex
- 300 timse slower…
- Correct
- Samophore
- 900 times slower…
- Correct
Bad. Accumulate to different places in memory. Solutions:
- Adjacent memory accumulator - they don’t write to same place - correct and faster
- false sharing - hardware still thinks cache is shared, but not because they actually share bytes but they are in same block
- note we do want true sharing for good locality.
- Spaced memory accumulator - make sure cache blocks don’t overlap - even faster if we manage to store value in different blocks
Even better: put accumulator inside a register
- 2x fater than spaced memory
H4 Parallel sort
Recall sequential quicksort: pick pivot, partition, sequentially sort each
- Parallel:
- model
- some thread produces sorting task for array segments
- a pool of threads consume task and do the sorting
- procedure
- If array is short
- Making thread has overhead (threshold may depend on machine), so do sequential sort
- Else
- pick pivot
- partition
- soart each half in different thread
- If array is short
- model
H3 Amdahl’s law
- total sequential time
- fraction of total time that can be sped up
- speed up factor
Results in performance
Maximum performance when
Exception: maybe speeding up one part of code speeds up something else